부스팅 (Boosting)
여러 개의 분류기가 순차적으로 학습 수행, 다음 분류기에게는 가중치 (weight)를 부여하면서 학습, 예측 진행한다. 예측 성능이 뛰어나 앙상블 학습을 주도한다. 학습 라운드를 차례로 진행하면서 각 예측이 틀린 데이터에 점점 가중치를 주는 방식이다. 라운드별로 잘못 분류된 데이터를 좀 더 잘 분류하는 모델로 만들어 최종 적으로 모델들의 앙상블을 만드는 방식으로 배깅 알고리즘이 처음 성능을 측정하기 위한 기준 (baseline) 알고리즘으로 많이 사용 된다면, 부스팅 알고리즘은 높은 성능을 내야 하는 상황에서 가장 좋은 선택지이다.

첫 번째 라운드 결과 모델에서 어떤 점은 오차가 큰 부분이다. 두 번째 라운드에서 오답으로 분류된 어떤 점에 가중치를 줘 학습한다. 다시 오류가 큰 다른 영역에 가중치를 둬 모델을 개발한다. 결과적으로, 틀린 부분만 집중해서 모델들을 순차적으로 만들고, 해당 모델들은 최종적으로 앙상블한다.
배깅과 부스팅의 차이점
| 1. 병렬화 가능 여부 |
|
| 2. 기준 추정치 |
|
| 3. 성능 차이 |
|
랜덤 포레스트 (Random Forest)

랜덤 포레스트는 지도 머신 러닝 알고리즘이다. 정확성, 단순성 및 유연성으로 인해 가장 많이 사용되는 알고리즘 중 하나이다. 분류 및 회귀 작업에 사용할 수 있다는 사실과 비선형 특성을 결합하면 다양한 데이터 및 상황에 매우 적합하다.
분류, 회귀 분석 등에 사용되는 앙상블 학습 방법의 일종으로, 훈련 과정에서 구성한 다수의 결정 트리로부터 부류 (분류) 또는 평균 예측치 (회귀 분석)를 출력함으로써 동작한다.
에이다부스트 (AdaBoost)
부스팅 알고리즘 중 대표적인 알고리즘이다. 약한 학습기가 순차적으로 오류 값에 대해 가중치를 부여한 예측 결정 기준을 모두 결합해 예측 수행한다. 매 라운드마다 인스턴스, 즉 개별 데이터의 가중치를 계산하는 방식이다. 매 라운드마다 틀린 값이 존재하고 해당 인스턴스에 가중치를 추가로 주어 가중치를 기준으로 재샘플링 (resampling)한다.
알고리즘
모든 샘플의 가중치 값을 데이터 개수를 기준으로 1/ N으로 초기화한 다음,

데이터의 가중치를 사용해 모델을 학습시킨다. 그 다음 해당 분류기의 오류를 계산한다.

해당 분류기의 가중치를 생성한다.

모델의 가중치를 사용하여 각 데이터의 가중치를 업데이트한다.
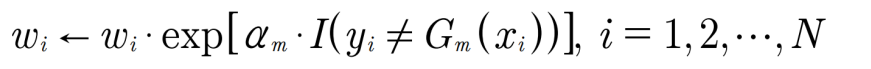
최종 결과물은 각 모델 가중치와 모델 결과값의 가중합을 연산하여 계산한다.

스텀프 (Stump)

스텀프 (stump)는 ‘그루터기’라는 뜻으로 나무의 윗부분을 자르고 아랫부 분만 남은 상태를 말한다. 에이다부스트에서 스텀프는 학습할 때 큰 나무를 사용하여 학습하는 것이 아니라 나무의 그루터기만을 사용하여 학습한다는 개념이다. 깊이 1 (depth) 또는 2 정도의 매우 간단한 모델을 여러 개 만들어 학습한 후, 해당 모델들의 성능을 에이다부스트 알고리즘을 적용하여 학습하는 형태이다.
example
import numpy as np
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
X = np.load("./titanic_x_train.npy")
y = np.load("./titanic_y_train.npy")
eclf = AdaBoostClassifier(base_estimator=DecisionTreeClassifier(max_depth=2), n_estimators=500)
cross_val_score(eclf, X, y, cv=5).mean()0.786320066019171# 비교군으로 RandomForestClassifier를 생성
from sklearn.ensemble import RandomForestClassifier
eclf = RandomForestClassifier(n_estimators=500)
cross_val_score(eclf, X, y, cv=5).mean()0.8031993905922683# GridSearchCV를 사용하여 가장 좋은 모델을 찾아 모델의 성능을 향상
eclf = AdaBoostClassifier(base_estimator=DecisionTreeClassifier(max_depth=2),n_estimators=500)
params = {"base_estimator__criterion" : ["gini", "entropy"],
"base_estimator__max_features" : [7,8,],
"base_estimator__max_depth" : [1,2],
"n_estimators": [23,24, 25, 26, 27],
"learning_rate": [0.4, 0.45, 0.5, 0.55, 0.6]
}
from sklearn.model_selection import GridSearchCV
grid = GridSearchCV(estimator=eclf, param_grid=params, cv=5, n_jobs=7)
grid = grid.fit(X, y)
grid.best_score_0.8358027042468101grid.best_params_{'base_estimator__criterion': 'gini',
'base_estimator__max_depth': 2,
'base_estimator__max_features': 7,
'learning_rate': 0.6,
'n_estimators': 26}grid.best_estimator_.feature_importances_array([0.15647766, 0.19060085, 0.09387801, 0.03365668, 0.0732818 ,
0.13875425, 0.03198129, 0.00819229, 0. , 0.02576316,
0. , 0. , 0. , 0.03949369, 0. ,
0.03247514, 0.02004646, 0.00972156, 0.0410272 , 0.00802741,
0.03259608, 0.02722659, 0. , 0. , 0.00572565,
0.01027984, 0.02079439])'Learning-driven Methodology > ML (Machine Learning)' 카테고리의 다른 글
| 15. TF-IDF (Term Frequency-Inverse Document Frequency) (0) | 2021.12.22 |
|---|---|
| 14. 소셜 네트워크 분석 (Social Network Analysis) (0) | 2021.12.22 |
| 12. 토픽 모델링 (Topic Modeling) (0) | 2021.12.22 |
| 11. 워드투벡터 (Word2Vec) (0) | 2021.12.22 |
| 10. 신경망 (Neural Network) (0) | 2021.12.15 |
