구조 점수 (Structure Score)
트리 모델을 다시 공식화한 후 다음을 사용하여 목적 값을 작성할 수 있다.
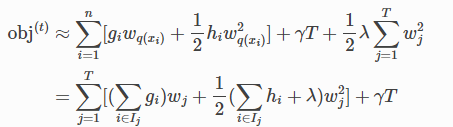
Ij={i|q(xi)=j}에 할당된 데이터 포인트의 인덱스 집합이다. 두 번째 줄에서 동일한 잎의 모든 데이터 포인트가 동일한 점수를 받기 때문에 합계의 인덱스를 변경했다. 다음을 정의하여 표현식을 더 압축할 수 있다.
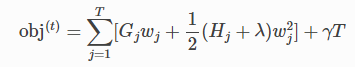
이 방정식에서 wj 형태는 서로 독립이다. 주어진 구조 q(x)에 대해 얻을 수 있는 최고 wj의 객관적 감소는 다음과 같다.
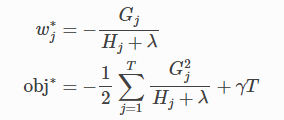
마지막 방정식은 트리 구조가 얼마나 좋은지를 측정한다. 그것은 q(x)이다.

그림을 보고 점수를 계산하는 방법을 살펴본다. 기본적으로 주어진 트리 구조에 대해 통계 gi 그리고 hi를 푸시한다.
그들이 속한 잎에 통계를 합산하고 공식을 사용하여 나무가 얼마나 좋은지 계산한다. 이 점수는 모델 복잡성도 고려한다는 점을 제외하고는 의사결정 트리의 불순도 측정과 유사하다.
트리 구조 배우기 (Learn the tree structure)
이제 나무가 얼마나 좋은지 측정할 수 있는 방법이 있으므로 가능한 모든 나무를 열거하고 가장 좋은 나무를 선택하는 것이 이상적이다. 실제로 이것은 다루기 어렵기 때문에 한 번에 한 수준의 트리를 최적화하려고 한다. 특히, 잎을 두 개의 잎으로 나누려고 시도하고 얻은 점수는 다음과 같다.
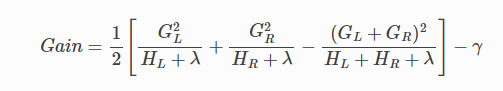
이 공식은 1) 새 왼쪽 잎의 점수, 2) 새 오른쪽 잎의 점수, 3) 원래 잎의 점수, 4) 추가 잎의 정규화로 분해될 수 있다. 여기서 중요한 사실을 알 수 있다. 이득이 다음보다 작은 경우 γ, 해당 분기를 추가하지 않는 것이 좋다. 이것이 바로 나무 기반 모델의 가지치기 (pruning) 기술이다. 지도 학습의 원리를 사용하면 이러한 기술이 작동하는 이유를 자연스럽게 이해할 수 있다.
실제 값 데이터의 경우 일반적으로 최적의 분할을 검색하려고 한다. 이를 효율적으로 수행하기 위해 다음 그림과 같이 모든 인스턴스를 정렬된 순서로 배치한다.
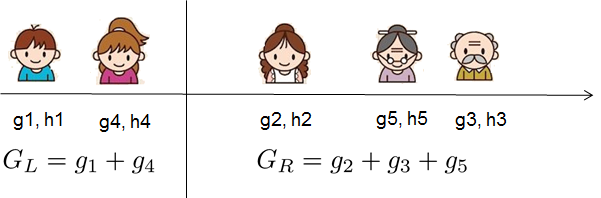
왼쪽에서 오른쪽으로 스캔하면 가능한 모든 분할 솔루션의 구조 점수를 계산하기에 충분하며 최상의 분할을 효율적으로 찾을 수 있다.
https://xgboost.readthedocs.io/en/stable/tutorials/model.html
Introduction to Boosted Trees — xgboost 1.6.0 documentation
XGBoost stands for “Extreme Gradient Boosting”, where the term “Gradient Boosting” originates from the paper Greedy Function Approximation: A Gradient Boosting Machine, by Friedman. The gradient boosted trees has been around for a while, and there
xgboost.readthedocs.io
'Learning-driven Methodology > ML (Machine Learning)' 카테고리의 다른 글
| [XGBoost] Python Package Introduction (2) (0) | 2022.05.09 |
|---|---|
| [XGBoost] Python Package Introduction (1) (0) | 2022.05.09 |
| [XGBoost] 트리 부스팅 (Tree Boosting) (1) (0) | 2022.05.06 |
| [XGBoost] 의사결정 트리 앙상블 (Decision Tree Ensembles) (0) | 2022.05.06 |
| [XGBoost] Boosted Trees (0) | 2022.05.06 |



