Data-driven Methodology/Spark
[Spark] Jupyter Lab
goatlab
2024. 7. 15. 15:53
728x90
반응형
SMALL
디렉토리 설정
cd work/
mkdir jupyter
cd jupyter/
주피터 랩 설치 및 환경 설정
pyenv activate py3_11_9
pip install jupyterlabjupyter lab --generate-config
처음 디렉토리로 이동하여 다음 명령을 실행한다.
cd .jupyter/
vim jupyter_lab_config.py
에디터에서 다음 코드를 c 객체 밑에 추가한다.
c.NotebookApp.ip = '0.0.0.0' # 모든 네트워크 요청 수신
c.NotebookApp.open_browser = False # 자동으로 웹 브라우저를 열지 않음
c.NotebookApp.port = 8888 # 주피터 랩 서버가 사용할 포트 번호
c.NotebookApp.token = '' # 주피터 랩 서버에 접속할 때 사용할 인증 토큰 (빈 문자열로 설정하면 토큰 인증 비활성화)
c.NotebookApp.password = '' # 주피터 랩 서버에 접속할 때 사용할 비밀번호 (빈 문자열로 설정하면 비밀번호 비활성화)
c.ServerApp.root_dir = '/home/ubuntu/work/jupyter' # 주피터 랩의 루트 디렉토리
다음 설정도 추가한다.
vim .bashrcexport PYSPARK_DRIVER_PYTHON="jupyter"
export PYSPARK_DRIVER_PYTHON_OPTS="lab"
쉘을 재시작한다.
source .bashrc
exec $SHELL
findspark는 PySpark를 사용할 때, python 환경에서 Spark를 쉽게 설정할 수 있도록 도와주는 유틸리티 패키지이다. Spark 환경 변수 설정의 번거로움을 덜어준다.
pip install findspark
인바운드 규칙에서 8888번 포트를 추가한다.

주피터 랩 실행
다음 명령어로 주피터 랩을 실행한다.
jupyter lab
런처에서 노트북 Python 3를 클릭하면 자동으로 루트 디렉토리에 ipynb 파일이 생성된다.
import findspark
findspark.init("/home/ubuntu/app/spark/spark-3.5.1-bin-hadoop3")
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("test").getOrCreate()
df = spark.read.parquet("/home/ubuntu/work/spark01/data/iris.parquet")
df.show(3)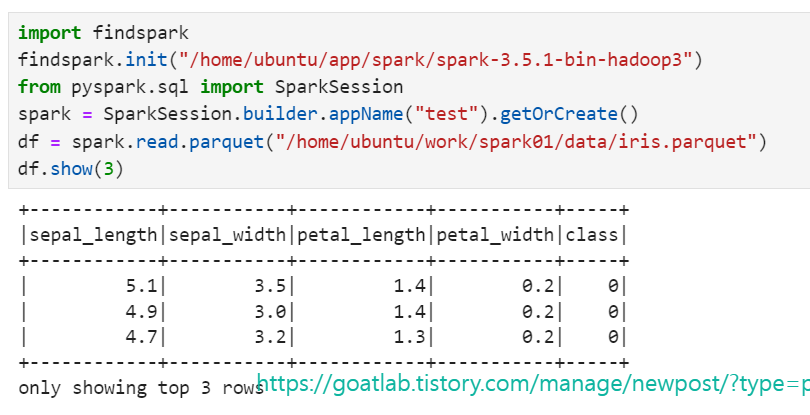
728x90
반응형
LIST