App Programming/MLops
[MLops] 모델 훈련
goatlab
2024. 8. 9. 16:24
728x90
반응형
SMALL
디렉토리 생성
opt 디렉토리에서 mlops-model 디렉토리를 생성한다.
mkdir mlops-model
mkdir dataset
cp /opt/mlops-crawler/result/watch_log.csv dataset/
패키지 설치
pip install -U numpy==1.26.4
pip install torch torchinfo scikit-learn icecream
main.py
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from icecream import ic
class WatchLogDataset(Dataset):
def __init__(self, df: pd.DataFrame):
self.df = df
self._preprocessing()
self.rating = torch.FloatTensor(df["rating"].values)
self.popularity = torch.FloatTensor(df["popularity"].values)
self.watch_seconds = torch.FloatTensor(df["watch_seconds"].values)
def _preprocessing(self):
target_columns = ["rating", "popularity", "watch_seconds"]
self.df = self.df[target_columns].drop_duplicates()
def __len__(self):
return len(self.rating)
def __getitem__(self, idx):
return self.rating[idx], self.popularity[idx], self.watch_seconds[idx]
class WatchLogPredictor(nn.Module):
def __init__(self, input_dim):
super(WatchLogPredictor, self).__init__()
self.fc1 = nn.Linear(input_dim, 64)
self.fc2 = nn.Linear(64, 32)
self.fc3 = nn.Linear(32, 1)
self.relu = nn.ReLU()
def forward(self, x):
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
df = pd.read_csv("./dataset/watch_log.csv")
train_df, valid_df = train_test_split(df, test_size=0.2, random_state=42)
train_dataset = WatchLogDataset(train_df)
valid_dataset = WatchLogDataset(valid_df)
train_dataloader = DataLoader(train_dataset, batch_size=64, shuffle=True)
valid_dataloader = DataLoader(valid_dataset, batch_size=64, shuffle=False)
model = WatchLogPredictor(input_dim=2)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
def train(model, train_dataloader, criterion, optimizer):
model.train()
total_loss = 0
print("this line")
ic()
for rating, popularity, watch_seconds in train_dataloader:
inputs = torch.cat((rating.unsqueeze(1), popularity.unsqueeze(1)), dim=1)
predictions = model(inputs).squeeze()
loss = criterion(predictions, watch_seconds)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(train_dataloader)
def evaluate(model, valid_dataloader, criterion):
model.eval()
total_loss = 0
with torch.no_grad():
for rating, popularity, watch_seconds in valid_dataloader:
inputs = torch.cat((rating.unsqueeze(1), popularity.unsqueeze(1)), dim=1)
predictions = model(inputs).squeeze()
loss = criterion(predictions, watch_seconds)
total_loss += loss.item()
return total_loss / len(valid_dataloader)
num_epoch = 30
for epoch in range(num_epoch):
train_loss = train(model, train_dataloader, criterion, optimizer)
valid_loss = evaluate(model, valid_dataloader, criterion)
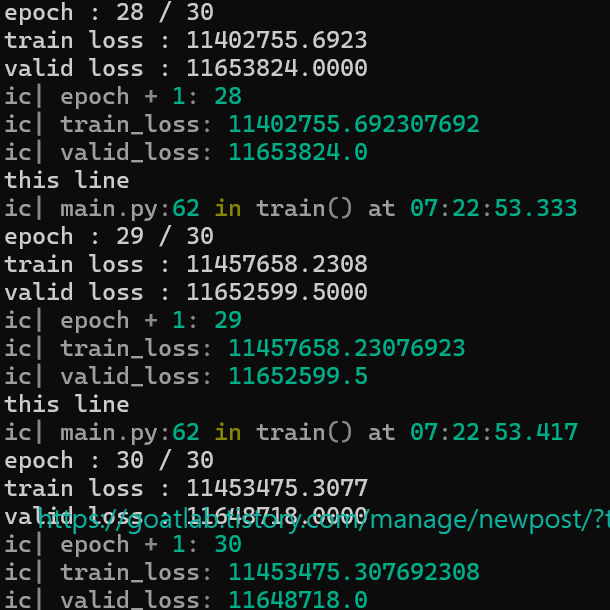
print(f"epoch : {epoch + 1} / {num_epoch}")
print(f"train loss : {train_loss:.4f}")
print(f"valid loss : {valid_loss:.4f}")
ic(epoch + 1)
ic(train_loss)
ic(valid_loss)
torch.save(model.state_dict(), "watch_time_predictor.pth")
모델 확인
model = WatchLogPredictor(input_dim=2)
print(model)
from torchinfo import summary
summary(model)
exit(0)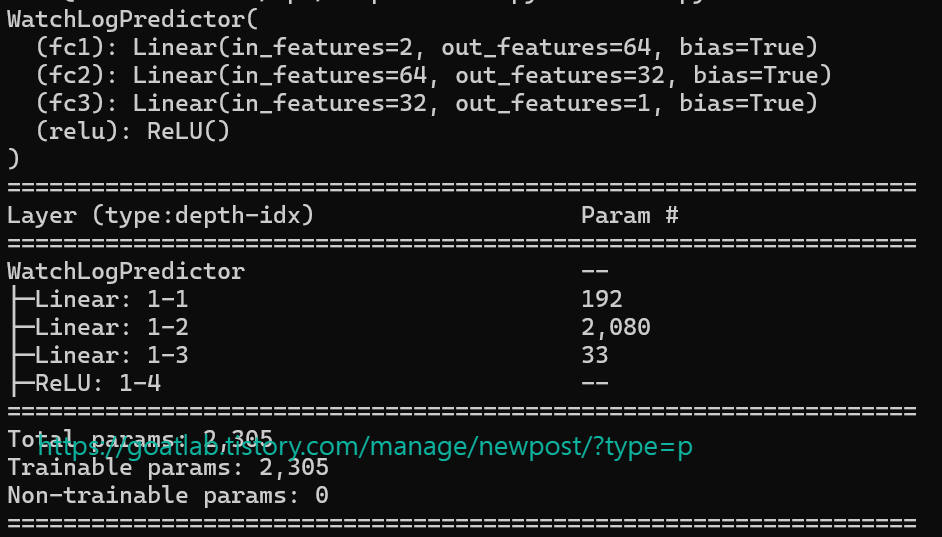
728x90
반응형
LIST