변환기 (Transducer)
변환기는 에너지를 한 형태에서 다른 형태로 변환하는 장치이다. 일반적으로 변환기는 한 형태의 에너지 신호를 다른 형태의 신호로 변환한다. 변환기는 전기 신호가 다른 물리적 양으로 변환되거나 그 반대로 변환되는 자동화, 측정 및 제어 시스템의 경계에서 종종 사용된다.
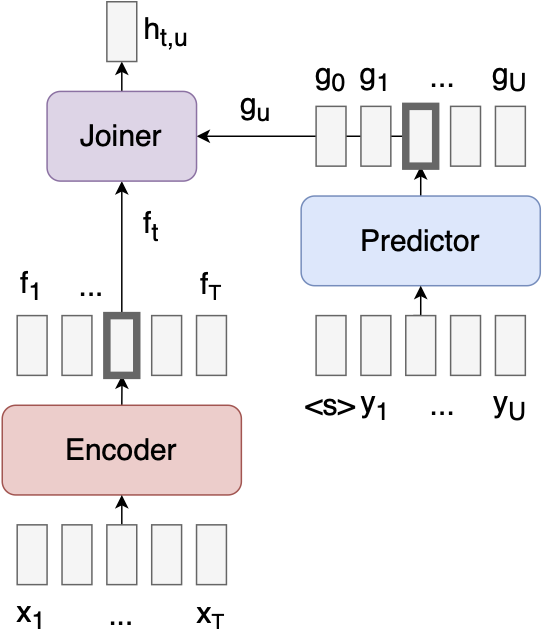
Transducer는 실시간 음성 인식 등 빠른 응답 속도를 요구하는 분야에 사용할 수 있는 Encoder, Decoder와 Joint Network 3개의 모듈로 구성된 구조이다. 음성에서 특징을 추출하는 Encoder, 글자에서 특징을 추출하는 Decoder와 앞선 두 특징을 결합해서 다음 글자를 예측하는 Joint Network로 구성되어 있다.
import torch
import string
import numpy as np
import itertools
from collections import Counter
from tqdm import tqdm
!pip install unidecode
import unidecode
!wget https://raw.githubusercontent.com/lorenlugosch/infer_missing_vowels/master/data/train/war_and_peace.txt
!pwd
먼저 표준 신경망을 사용하여 encoder, predictor 및 joiner를 정의한다.
NULL_INDEX = 0
encoder_dim = 1024
predictor_dim = 1024
joiner_dim = 1024
인코더 (Encoder)
인코더는 가변 길이 시퀀스를 입력으로 사용할 수 있는 모든 네트워크이다. 따라서, RNN, CNN 및 self-attention / Transformer 인코더가 모두 작동한다.
class Encoder(torch.nn.Module):
def __init__(self, num_inputs):
super(Encoder, self).__init__()
self.embed = torch.nn.Embedding(num_inputs, encoder_dim)
self.rnn = torch.nn.GRU(input_size=encoder_dim, hidden_size=encoder_dim, num_layers=3, batch_first=True, bidirectional=True, dropout=0.1)
self.linear = torch.nn.Linear(encoder_dim*2, joiner_dim)
def forward(self, x):
out = x
out = self.embed(out)
out = self.rnn(out)[0]
out = self.linear(out)
return out
Predictor
predictor는 모든 인과 (causal) 네트워크 (미래를 볼 수 없음)이다. 즉, 단방향 RNN, causal 컨볼루션 또는 마스크된 self-attention이다.
class Predictor(torch.nn.Module):
def __init__(self, num_outputs):
super(Predictor, self).__init__()
self.embed = torch.nn.Embedding(num_outputs, predictor_dim)
self.rnn = torch.nn.GRUCell(input_size=predictor_dim, hidden_size=predictor_dim)
self.linear = torch.nn.Linear(predictor_dim, joiner_dim)
self.initial_state = torch.nn.Parameter(torch.randn(predictor_dim))
self.start_symbol = NULL_INDEX # In the original paper, a vector of 0s is used; just using the null index instead is easier when using an Embedding layer.
def forward_one_step(self, input, previous_state):
embedding = self.embed(input)
state = self.rnn.forward(embedding, previous_state)
out = self.linear(state)
return out, state
def forward(self, y):
batch_size = y.shape[0]
U = y.shape[1]
outs = []
state = torch.stack([self.initial_state] * batch_size).to(y.device)
for u in range(U+1): # need U+1 to get null output for final timestep
if u == 0:
decoder_input = torch.tensor([self.start_symbol] * batch_size, device=y.device)
else:
decoder_input = y[:,u-1]
out, state = self.forward_one_step(decoder_input, state)
outs.append(out)
out = torch.stack(outs, dim=1)
return out
Joiner
조이너는 각 (t,u) 인덱스에 독립적으로 적용되는 하나의 hidden layer가 있는 순방향 네트워크 / MLP이다 (hidden layer의 선형 부분은 인코더와 예측기에 포함되어 있으므로 여기서는 비선형성을 수행한 다음 출력 레이어를 수행함).
class Joiner(torch.nn.Module):
def __init__(self, num_outputs):
super(Joiner, self).__init__()
self.linear = torch.nn.Linear(joiner_dim, num_outputs)
def forward(self, encoder_out, predictor_out):
out = encoder_out + predictor_out
out = torch.nn.functional.relu(out)
out = self.linear(out)
return out
Transducer model + loss function
인코더, predictor 및 joiner를 사용하여 tranducer 모델과 해당 손실 함수를 구현한다.
class Transducer(torch.nn.Module):
def __init__(self, num_inputs, num_outputs):
super(Transducer, self).__init__()
self.encoder = Encoder(num_inputs)
self.predictor = Predictor(num_outputs)
self.joiner = Joiner(num_outputs)
if torch.cuda.is_available(): self.device = "cuda:0"
else: self.device = "cpu"
self.to(self.device)
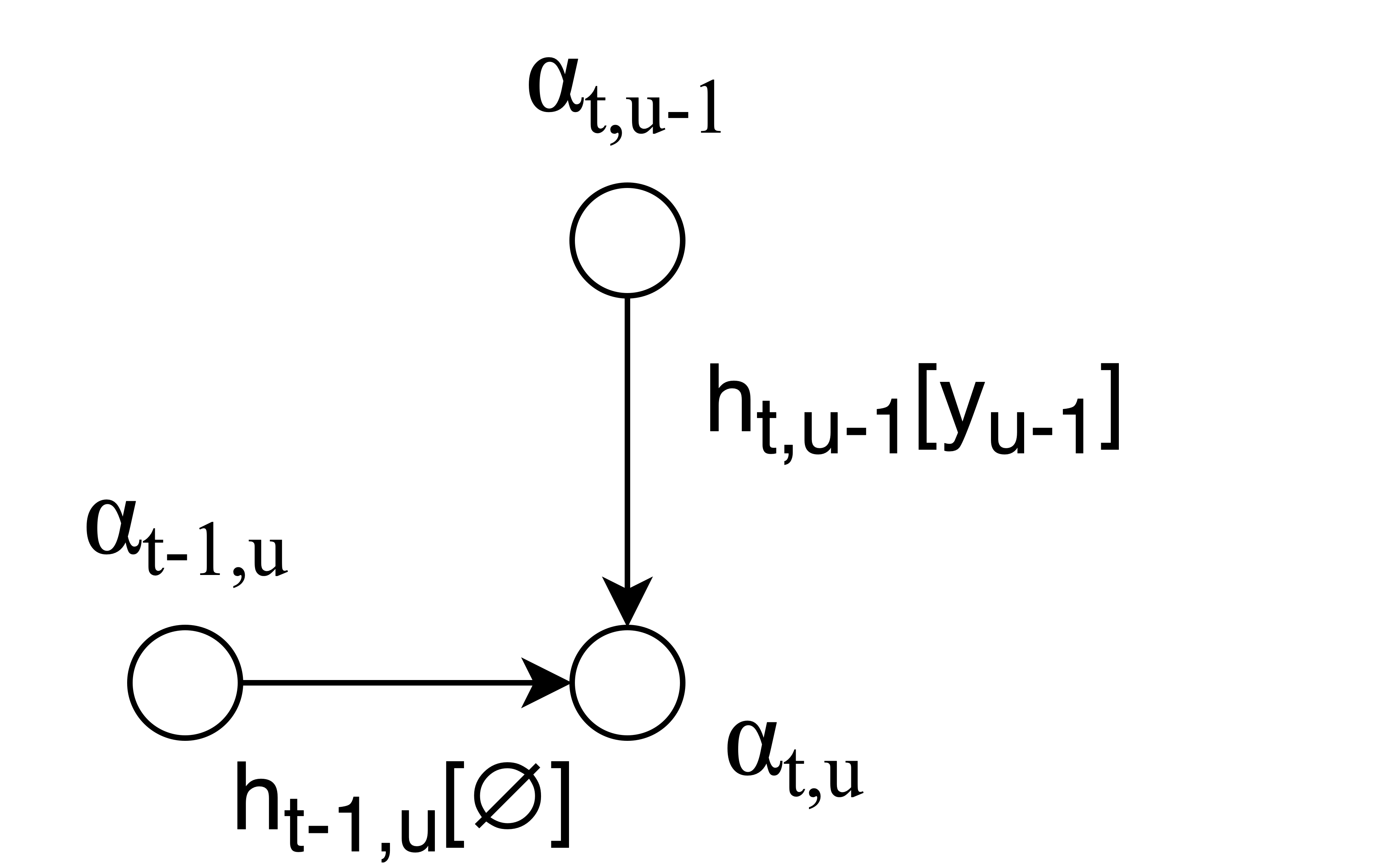
def compute_forward_prob(self, joiner_out, T, U, y):
"""
joiner_out: tensor of shape (B, T_max, U_max+1, #labels)
T: list of input lengths
U: list of output lengths
y: label tensor (B, U_max+1)
"""
B = joiner_out.shape[0]
T_max = joiner_out.shape[1]
U_max = joiner_out.shape[2] - 1
log_alpha = torch.zeros(B, T_max, U_max+1, device=model.device)
for t in range(T_max):
for u in range(U_max+1):
if u == 0:
if t == 0:
log_alpha[:, t, u] = 0.
else: #t > 0
log_alpha[:, t, u] = log_alpha[:, t-1, u] + joiner_out[:, t-1, 0, NULL_INDEX]
else: #u > 0
if t == 0:
log_alpha[:, t, u] = log_alpha[:, t,u-1] + torch.gather(joiner_out[:, t, u-1], dim=1, index=y[:,u-1].view(-1,1) ).reshape(-1)
else: #t > 0
log_alpha[:, t, u] = torch.logsumexp(torch.stack([
log_alpha[:, t-1, u] + joiner_out[:, t-1, u, NULL_INDEX],
log_alpha[:, t, u-1] + torch.gather(joiner_out[:, t, u-1], dim=1, index=y[:,u-1].view(-1,1) ).reshape(-1)
]), dim=0)
log_probs = []
for b in range(B):
log_prob = log_alpha[b, T[b]-1, U[b]] + joiner_out[b, T[b]-1, U[b], NULL_INDEX]
log_probs.append(log_prob)
log_probs = torch.stack(log_probs)
return log_probs
def compute_loss(self, x, y, T, U):
encoder_out = self.encoder.forward(x)
predictor_out = self.predictor.forward(y)
joiner_out = self.joiner.forward(encoder_out.unsqueeze(2), predictor_out.unsqueeze(1)).log_softmax(3)
loss = -self.compute_forward_prob(joiner_out, T, U, y).mean()
return loss
먼저, 순방향 알고리즘이 가능한 모든 정렬을 계산할 수 있는 짧은 입력/출력 쌍을 사용하여 가능한 모든 정렬의 합계 (로그 공간, logsumexp)를 실제로 올바르게 계산하는지 확인한다.
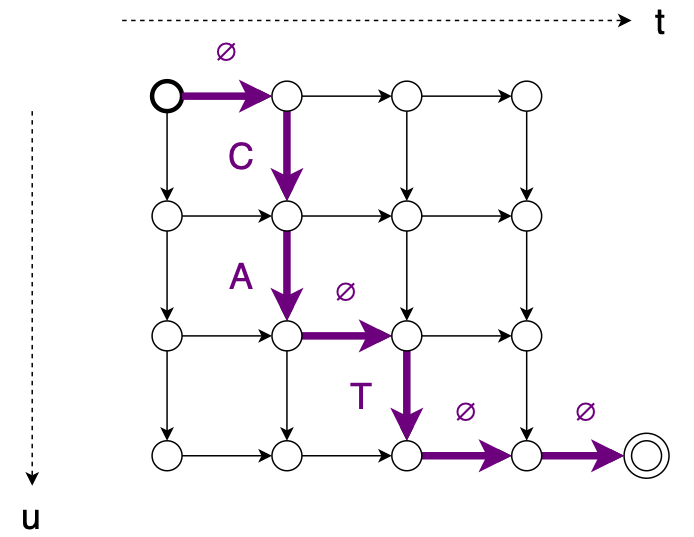
def compute_single_alignment_prob(self, encoder_out, predictor_out, T, U, z, y):
"""
Computes the probability of one alignment, z.
"""
t = 0; u = 0
t_u_indices = []
y_expanded = []
for step in z:
t_u_indices.append((t,u))
if step == 0: # right (null)
y_expanded.append(NULL_INDEX)
t += 1
if step == 1: # down (label)
y_expanded.append(y[u])
u += 1
t_u_indices.append((T-1,U))
y_expanded.append(NULL_INDEX)
t_indices = [t for (t,u) in t_u_indices]
u_indices = [u for (t,u) in t_u_indices]
encoder_out_expanded = encoder_out[t_indices]
predictor_out_expanded = predictor_out[u_indices]
joiner_out = self.joiner.forward(encoder_out_expanded, predictor_out_expanded).log_softmax(1)
logprob = -torch.nn.functional.nll_loss(input=joiner_out, target=torch.tensor(y_expanded).long().to(self.device), reduction="sum")
return logprob
Transducer.compute_single_alignment_prob = compute_single_alignment_prob'Linguistic Intelligence > Speech Recognition' 카테고리의 다른 글
| [Speech Recognition] wav2vec2 모델을 이용하여 음성 인식 프로젝트 (0) | 2024.08.06 |
|---|---|
| [Speech Recognition] wav2vec2 (0) | 2024.08.06 |
| [Speech Recognition] 연결주의 시간 분류 (Connectionist Temporal Classification) (0) | 2024.07.16 |
| [Speech Recognition] 레거시 음성 모델 (Legacy Acoustic Model) (0) | 2024.07.03 |
| 자동 음성 인식 (Automatic Speech Recognition) (0) | 2024.07.03 |



