속도 및 메모리 사용량 최적화
많은 부스팅 도구는 의사결정 트리 학습을 위해 사전 정렬 기반 알고리즘 (ex: xgboost의 기본 알고리즘)을 사용한다. 간단한 솔루션이지만 최적화하기가 쉽지 않다.
LightGBM은 히스토그램 기반 알고리즘을 사용하여 연속적인 특징 (속성) 값을 개별 bin으로 묶는다. 이렇게 하면 훈련 속도가 빨라지고 메모리 사용량이 줄어든다. 히스토그램 기반 알고리즘의 장점은 다음과 같다.
| 각 분할에 대한 이득 계산 비용 절감 |
|
| 추가 속도 향상을 위해 히스토그램 빼기 |
|
| 메모리 사용량 줄이기 |
|
| 분산 학습을 위한 통신 비용 절감 |
희소 최적화 (Sparse Optimization)
희소 특성에 대한 히스토그램만 구성하면 된다. O(2 * #non_zero_data)
정확도 최적화 (Optimization in Accuracy)
1. 리프 방식 (최상 우선) 트리 성장
대부분의 의사 결정 트리 학습 알고리즘은 다음 이미지와 같이 수준 (깊이)별로 트리를 성장시킨다.
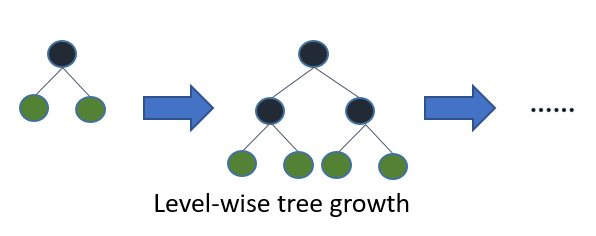
LightGBM은 나무를 잎사귀로 자란다 (최상 우선). 최대 델타 손실이 있는 잎을 선택하여 성장할 것이다. 고정된 #leaf는 리프 방식 알고리즘은 레벨 방식 알고리즘보다 손실이 적은 경향이 있다.
Leaf-wise는 #data이 작을 때 과적합을 유발할 수 있으므로 LightGBM에는 트리 깊이를 제한하는 max_depth 매개변수가 포함된다. 그러나 max_depth가 지정된 경우에도 나무는 여전히 잎사귀로 자란다.

2. 범주형 기능에 대한 최적 분할
원-핫 인코딩으로 범주형 기능을 표현하는 것이 일반적이지만 이 접근 방식은 트리 학습자에게 차선책이다. 특히, cardinality가 높은 범주형 기능의 경우 원-핫 기능을 기반으로 구축된 트리는 균형이 맞지 않는 경향이 있으며 우수한 정확도를 달성하기 위해 매우 깊이 성장해야 한다.
원-핫 인코딩 대신에 최적의 솔루션은 범주를 2개의 하위 집합으로 분할하여 범주 기능을 분할하는 것이다. 기능에 k범주가 있는 경우 가능한 파티션이 있다. 그러나 회귀 트리에 대한 효율적인 솔루션이 있다. 최적의 파티션을 찾아야 한다. 2^(k-1) - 1O(k * log(k))
기본 아이디어는 각 분할에서 훈련 목표에 따라 범주를 정렬하는 것이다. 보다 구체적으로, LightGBM은 누적 값 (sum_gradient / sum_hessian)에 따라 히스토그램 (범주형 기능의 경우)을 정렬한 다음 정렬된 히스토그램에서 최상의 분할을 찾는다.
https://lightgbm.readthedocs.io/en/latest/Features.html#optimization-in-speed-and-memory-usage
Features — LightGBM 3.3.2.99 documentation
This is a conceptual overview of how LightGBM works[1]. We assume familiarity with decision tree boosting algorithms to focus instead on aspects of LightGBM that may differ from other boosting packages. For detailed algorithms, please refer to the citation
lightgbm.readthedocs.io
'Learning-driven Methodology > ML (Machine Learning)' 카테고리의 다른 글
| [LightGBM] 매개변수 조정 (Parameters Tuning) (1) (0) | 2022.06.28 |
|---|---|
| [LightGBM] Features (2) (0) | 2022.06.28 |
| [LightGBM] Python 패키지 (2) (0) | 2022.06.28 |
| [LightGBM] Python 패키지 (1) (0) | 2022.06.28 |
| LightGBM (0) | 2022.06.28 |



